
Secure Access To Opensearch on AWS
Table of Contents
At Buffer, we have been performing on a superior admin dashboard for our client advocacy team. This admin dashboard incorporated a a lot more impressive search functionality. Nearing the stop of the project’s timeline, we have been prompted with the substitute of managed Elasticsearch on AWS with managed Opensearch. Our venture has been developed on top of more recent variations of the elasticsearch consumer which all of a sudden did not help Opensearch.
To increase more gas to the hearth, OpenSearch purchasers for the languages we use, did not but support clear AWS Sigv4 signatures. AWS Sigv4 signing is a requirement to authenticate to the OpenSearch cluster employing AWS credentials.
This meant that the path ahead was riddled with just one of these options
- Go away our look for cluster open to the globe without having authentication, then it would function with the OpenSearch consumer. Unnecessary to say, this is a big NO GO for noticeable motives.
- Refactor our code to deliver uncooked HTTP requests and carry out the AWS Sigv4 mechanism ourselves on these requests. This is infeasible, and we wouldn’t want to reinvent a customer library ourselves!
- Develop a plugin/middleware for the client that implements AWS Sigv4 signing. This would get the job done at first, but Buffer is not a huge team and with continual company upgrades, this is not a little something we can reliably preserve.
- Switch our infrastructure to use an elasticsearch cluster hosted on Elastic’s cloud. This entailed a substantial amount of work as we examined Elastic’s Terms of Company, pricing, necessities for a protected networking set up and other time-expensive actions.
It seemed like this project was caught in it for the extensive haul! Or was it?
Wanting at the situation, below are the constants we just can’t feasibly adjust.
- We just cannot use the elasticsearch consumer any longer.
- Switching to the OpenSearch consumer would get the job done if the cluster was open up and essential no authentication.
- We cannot leave the OpenSearch cluster open to the earth for apparent causes.
Wouldn’t it be great if the OpenSearch cluster was open up ONLY to the applications that need to have it?
If this can be completed, then those people apps would be capable to join to the cluster without authentication enabling them to use the current OpenSearch client, but for everything else, the cluster would be unreachable.
With that stop purpose in brain, we architected the pursuing solution.
Piggybacking off our new migration from self-managed Kubernetes to Amazon EKS
We recently migrated our computational infrastructure from a self-managed Kubernetes cluster to an additional cluster that’s managed by Amazon EKS.
With this migration, we exchanged our container networking interface (CNI) from flannel to VPC CNI. This entails that we eradicated the overlay/underlay networks break up and that all our pods were now acquiring VPC routable IP addresses.
This will become more applicable going forward.
Block cluster entry from the outside the house entire world
We developed an OpenSearch cluster in a personal VPC (no world-wide-web-dealing with IP addresses). This indicates the cluster’s IP addresses would not be reachable more than the web but only to inside VPC routable IP addresses.
We included a few security teams to the cluster to command which VPC IP addresses are permitted to arrive at the cluster.
Create automations to management what is allowed to accessibility the cluster
We created two automations operating as AWS lambdas.
- Stability Team Supervisor: This automation can execute two procedures on-need.
- -> Add an IP tackle to a person of people three protection teams (the a single with the the very least amount of procedures at the time of addition).
- -> Remove an IP tackle just about everywhere it appears in individuals 3 protection teams.
- Pod Lifecycle Auditor: This automation operates on schedule and we’ll get to what it does in a instant.
We additional an InitContainer to all pods needing entry to the OpenSearch cluster that, on-begin, will execute the Protection Team Manager automation and ask it to insert the pod’s IP tackle to one of the protection groups. This enables it to access the OpenSearch cluster.
In real life, points happen and pods get killed and they get new IP addresses.For that reason, on timetable, the Pod Lifecycle Auditor runs and checks all the whitelisted IP addresses in the 3 stability groups that help accessibility to cluster. It then checks which IP addresses need to not be there and reconciles the safety teams by inquiring the Security Team Manager to take out people IP addresses.
Below is a diagram of how it all connects together
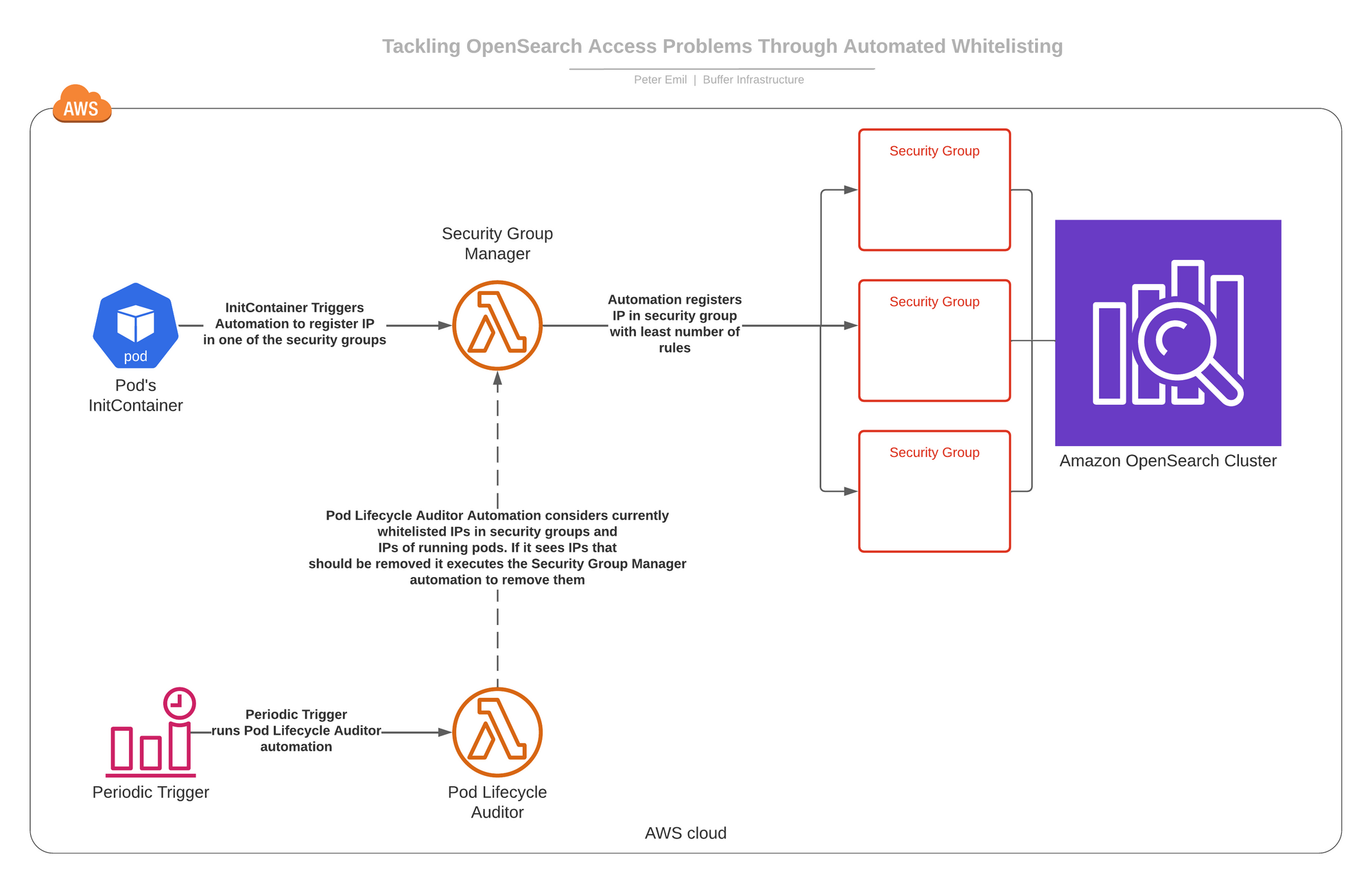
Why did we generate three stability groups to manage obtain to the OpenSearch cluster?
Since protection teams have a highest limit of 50 ingress/egress principles. We anticipate that we will not have far more than 70-90 pods at any provided time needing accessibility to the cluster. Acquiring three stability teams sets the restrict at 150 guidelines which feels like a harmless location for us to start out with.
Do I need to host the Opensearch cluster in the exact VPC as the EKS cluster?
It depends on your networking set up! If your VPC has personal subnets with NAT gateways, then you can host it in any VPC you like. If you really do not have private subnets, you want to host both of those clusters in the identical VPC due to the fact VPC CNI by default NATs VPC-exterior pod targeted traffic to the internet hosting node’s IP address which invalidates this solution. If you turn off the NAT configuration, then your pods cannot get to the internet which is a even bigger issue.
If a pod gets trapped in CrashLoopBackoff state, will not the huge quantity of restarts exhaust the 150 guidelines restrict?
No, for the reason that container crashes in just a pod get restarted with the identical IP handle inside the identical pod. The IP Address isn’t transformed.
Are not all those automations a single-point-of-failure?
Indeed they are, which is why it is crucial to tactic them with an SRE frame of mind. Ample checking of these automations combined with rolling deployments is critical to having trustworthiness here. At any time considering the fact that these automations have been instated, they’ve been very secure and we did not get any incidents. However, I snooze quick at night being aware of that if one of them breaks for any purpose I’ll get notified way right before it gets a obvious dilemma.
I accept that this option is not best but it was the fastest and simplest solution to put into action with out requiring ongoing routine maintenance and without having delving into the method of on-boarding a new cloud supplier.
Over to you
What do you believe of the method we adopted below? Have you encountered equivalent predicaments in your organization? Ship us a tweet!





